
 …this is the thread that just keeps on giving and giving…ughhh…lol…
…this is the thread that just keeps on giving and giving…ughhh…lol… 
Why is my pNode executing DoS Attacks?
Pnode is not running the same code as vnode, system resources do not allow for that to happen. Pnode uses lightweight mobile computing, vnode requires 8 cpu cores bare minimum and always pegs out the processor at 200 percent
You are absolutely wrong about vNodes requiring this much computing power.
I run a large amount of vNodes and only see small spikes when they are active.
Perhaps you mean vNodes have high resource usage when first being created? This would be an understandable action as they have to download previous blockchain information.
Could you link me to the page where it gives min system requirements to run a vnode?
Do you not run a vNode?
Specs were given to make sure ample amount of resources were available for a vNode to run properly.
I still never see high utilization unless for short bursts while my nodes are actively earning.
So you don’t want to direct me to that link of min specs required? Okay.
I used to, I could spin up another one to prove a point and report back in 3 days but from what I had found in the past is the codebase is very heavy and it computes ALOT when fully synced (it is a clone of eth2 basically so it does have capability of being quite the beast as far as resource intensity)
No, I don’t want to and don’t have to. I’m not a dev or team member but a community member. I’m also on mobile atm. You can search the forum just like everyone else.
Let’s do this. Spin one up and report back in 3 days. I guarantee you’re wrong in regards to resource utilization. After the initial sync of previous information nodes fall pretty much dormant.
1 Like
okay I will, maybe I am wrong we will see. I just did a quick search and found this : How to run Incognito Chain Full Node on Mainnet
so perhaps this device will run stable with full node
1 Like
My Vnode hardly takes anything when ‘ready/idle’. I can’t say I have watched it when its actively working… I will try to catch it next time around.
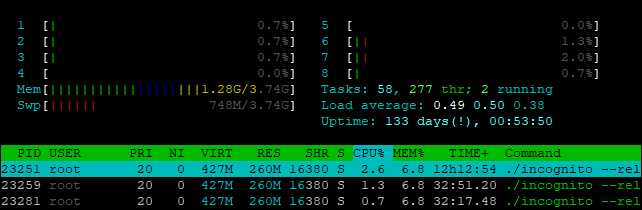
2 Likes
The code base has been written from scratch, there was no cloning involved when starting this project. Obviously it uses logic, and systems that have been proven their value in other blockchains.
where can we found the vNode code ? i dont find it on incognito’s github
8 cores are absolutely not necessary, I run my vNode on a 2 core VPS and there is 2 other chain nodes running on it.
I did exactly this, and not only it failed to sync 3 of the 8 shards, it also continued to consume terra bytes of data after the initial sync (with 3 broken shards). See my post: vnode syncing error - Validators - Incognito
When did you do this? What version were you running?
2021-04-05 18:26:28.366 incognito.go:96 [INF] Server log: Version 1.19.0-beta
I also uploaded the full log https://ufile.io/ue9d125l
@0xkumi was trying to help further inspect what was going on. I’m still waiting for any findings.
Ok following up on a chat elsewhere. Original poster here. Since everyone is claiming I didn’t follow up. See attached screen shot where nobody got back to me. Those logs and info I presented above speak for themselves. What more did they need? What can support or development do to change what the logs already show what was happening? The only question in my mind was is it intentional or not? Nobody has ever provided a reasonable explanation to this day.

Peter last logged in on April 9th, three days before your first followup.
You may be unaware that on that week the growth and support teams were let go. Including Peter. So you’ve been waiting in vain for someone to contact you when that person is no longer around to do so. That’s why no one has responded to you. Not because you discovered their evil DDoS plans ** maniacal cackle and tenting of hands **.
I’m sorry your Node is misbehaving. Other pNodes do not have this problem. Why yours does, is currently unknowable without a diagnostic inspection of your unit.
If you do not trust the team to do the inspection remotely, then it’s unlikely anyone will ever know why your Node began a flood of network traffic. To each his own.
That said – to take your singular experience and brush the entire project with it is disingenuous. There are plenty of other pNodes out there; many being monitored with the same scrutiny you applied to yours. And yet those pNodes owners have not signaled a similar experience. To a casual observer, this might suggest your experience is an outlier. While that absolutely does not justify your experience, it also does not make it indicative of the project as a whole either.
At the end of the day, you have every right to be skeptical and have a negative view of the project. After all, that has been your experience. But it is your experience, and not one shared by much anyone else at this point. Others may have a negative view for different reasons, but yours stands alone as the only one borne out of a suspected DoS campaign. You are free to wave that flag however you’d like, but you are not free to demand that everyone take that as an undeniable truth about the project because it’s simply not true.
3 Likes
Thank you. I said above that nobody has explained it. Your message now was more info than anyone has given me to this point.
Put yourself in my shoes and he experience that I had. You would likely be skeptical and/or suspicious as well. I have tried to be very careful in describing this. A DOS attack is a DOS attack. I know what it was doing. As I said above, the only thing I didnt/don’t 100% know for sure is whether it was intentional or not. But your explanation at least gives some weight to the alternative possibility that it was unintentional. Better than the no answers that I was given in the past. And I was unaware that the leadership had changed, but would have thought the inbox was monitored by someone. Thanks for letting me know that. If your explanation is correct, then it must have got infected unintentionally. But I believe it came to me that way, because it’s behavior was as described from the very start.
1 Like
Through no fault of your own, I believe your initial posts just had bad timing. The first few months of this year the team was in the midst of some self-inflicted turmoil with the project. To boot, your followups came during realignment of the team & project and unfortunately just fell through the cracks. It is no excuse, but it is the reality of what happened.
Support is now handled directly by the developers. This is good because it removes an intermediary layer (the old support team) between the end user and the developers. But it’s also bad because the developers are also quite busy … uh, developing. So following through on support requests sometimes takes much longer than it used to take.
With the current focus on slashing and Privacy v.2, it may take time for your case to be addressed. I would suggest starting a new support request with @ support, so you can at least get in the queue. Bring a book though, you may be there a while.
4 Likes