
Apology for delayed response @duc…but indeed a very very grateful and thankful and enthusiastic response on my part to your post… 


Shard stall
@Mike_Wagner, I’m looking for @duc to confirm this, but I think the move for more pending slots is with the idea of releasing all the slots. Currently I see anywhere between 128-152 nodes in pending slots on each shard. That is an incredibly long time to wait at the moment since they are only swapping out 5 at a time. When they release all the slots, they will be swapping out 32 at a time. Bringing the epoch pending time down to 4-5 epochs (less than a day) depending on how many nodes in front of you dont sync properly. Am I right here @duc?
Another weird thing I just encountered was I had a pending node that went into committee. During that, it stated 2 epochs before it went back into pending (instead of back to waiting). It just finished committee and indeed went back to pending. I’ve never seen that before.

2 Likes
It is true the pending pool will need to be much larger to support all 32 slots as fixed slots are released. However I based my statement on this private chat with support earlier this month about fixing pNodes with Vote Stats of 0%:

I’ve been watching the same thing since the new rules went into effect on Saturday. I think it could be a symptom of a bigger issue though.
The waiting pool is no longer being shuffled. At all. Previously – at the beginning of each epoch the nodes in the waiting pool were shuffled. Later in that same epoch, 32 randomly selected nodes from random, non-sequential positions were pulled into the 8 shard pending lists. A node’s position in the waiting list did not factor into when a node moved to a pending list. A node in position 1 was just as likely to enter a shard’s pending list as the node in the very last position or any random position between.
If you searched for your node(s) by the BLS mining key each epoch, you would see the position in the waiting list change every epoch.
However now the waiting pool appears to no longer be shuffled. A node will now stay in the same position relative to the nodes immediately before and after it in the list. And nodes are now pulled only from the top of the list, not from random, non-sequential positions.
Here are the last five nodes in the waiting pool of Epoch 3479.

Here are the same five nodes in the waiting pool of Epoch 3480. Same order, just moved up a few positions.

Here are five nodes from the middle of the waiting pool in Epoch 3479.

And here are the same five nodes in the waiting pool of Epoch 3480. Again – same order, just moved up 50 positions.

Not shuffled. Moved up 50 index positions. And not shuffled.
Finally here are the five nodes at the top of the waiting list for Epoch 3479.
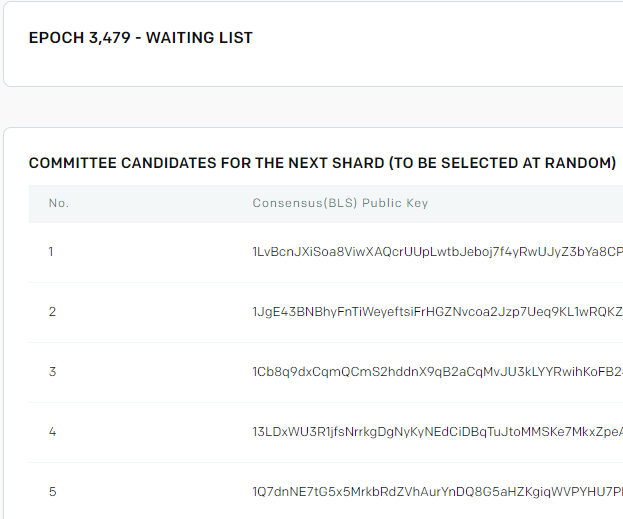
And here are the same nodes, after nodes are assigned to the 8 shard pending lists in Epoch 3480.





Each of those 5 nodes has moved to a shard pending list in Epoch 3480. Clearly no longer “SELECTED AT RANDOM” as the list header states.
One of my nodes has had the misfortune to be in the very last index position when the new rules went into effect. It has remained at the back of the list since this weekend. Based on the above observations, it could only enter the waiting pool committee once 99.5% of all nodes are already in the waiting pool.
As for your observation – it does appear nodes exiting committee are returned to the top of the list of nodes in the waiting pool where they immediately move back into the pending pool. Nodes being added to each shard’s pending list seem to be a mixture of nodes just released from committee AND nodes from the waiting list.
And to further complicate things, I think the new unstaking flow is broken. Before the weekend update, it was easy to see the new unstaking flow in action for new Unstaking Requests. Unstaking Requests were fulfilled about 2-3 hours after being submitted. Here 9 nodes submit Unstaking Requests which are fulfilled about 2.5 hours later.

However now we can see that Unstaking Requests are not being fulfilled in such a timely or orderly manner.

The 7 requests appear to be eventually fulfilled, albeit at random intervals not commiserate with submission requests. This also assumes that all these Unstaked transactions correlate to the shown Unstaking Requests and not any of the ~45 v.1 Unstaking Requests still waiting for committee selection to unstake.

It does appear something well beyond “longer time in the pending pool” has significantly altered the way candidate Nodes flow in the waiting pool, pending pool and even affects new v.2 Unstaking Requests.
6 Likes


@Mike_Wagner, As I said earlier, Im still looking for confirmation from @duc, but this info you provided is super helpful. My assumption was, let’s say your node was in committee. It runs its two cycles and then goes back to waiting. As it goes into waiting, it is assigned at random where in the cue it goes. So, when you look at your node status, it will give you a countdown as to how many epochs you have before going into pending. So, that would be the 1st layer of randomness. Now, as a 2nd layer of randomness, as other nodes get sent back to waiting, they may be put in front or back of you in the waiting list. Now that makes that waiting epoch number less reliable as an indicator as to when you are actually going to start pending, BUT it would still make sense what you are seeing above when you see a small group of nodes heading up the ranks together while they are waiting to pop pending. However, I thought the pending process was linear. Once you go pending, you are in the back of the line and simply work your way up as they pull groups of nodes to go into committee next. Simple enough right? What I saw today was my node go from committee straight to the back of the line in pending. This does not make any sense to me. But, at this point @Support , if you are trying to use this time to assess results and problems from the new workflow, you’re going to have to be waaaaaaaaaay more specific on exactly how this is all working. No user can help you guys troubleshoot problems if they dont know what they are looking at, or what to look for.
3 Likes
The committes page can be hard to understand.
Let’s break it down.
COMMITTEE LISTS
At the top of the page are lists for the Beacon Committee and each of the 8 Shards (0-7).

The Beacon Committee is currently run by the Incognito Team. The seven beacon nodes are fixed and do not change.
Next are the Committee Lists; Shards 0-7 with 32 validators per each shard.

through

Index 1-22 of each shard represents a validator currently run by the Incognito Team. 22 * 8 = 176 fixed validators. These 176 validators (the first 22 per shard) do not change.
Index 23-32 of each shard are the 10 community validators. These are swapped out 5 at a time each epoch. The nodes in index slots 23-27 exit the committee at the end of the epoch/beginning of next epoch. The nodes in index slots 28-32 then move up to slots 23-27. 5 new nodes from the top of the corresponding shard pending list are moved into committee list, to index slots 28-32 in the same order as they appear in the pending list.
The previous process would swap 4 nodes each epoch, but otherwise this is the same as the previous process.
THE WAITING LIST

This is the big list of validators that have not been selected for committee. As the header reads – TO BE SELECTED AT RANDOM. Indeed nodes were previously selected at random. They are no longer.
Nodes are moved to a shard pending list directly from the top of the list.
This is different than the previous process.
The order of this list is not changing.
This is different than the previous process.
Nodes exiting committee should join this list. This is no longer happening.
This is different than the previous process.
THE PENDING LIST

This is the list of all the validators plucked from the above waiting list, in preparation to join the committee lists at the top of the page. While in this list, a node will sync the assigned shard’s chain. This used to be a much smaller period of time. It is now growing.
The order of this list does not change from epoch to epoch. Validators are pulled from the top of each shard’s list to join committee. Newly assigned validators from the waiting list join the assigned shard’s pending list at the bottom.
Other than the (still) increasing size of each shard’s list, this is the same as the previous process.
It would not have been possible to know which nodes would become validators, except for that short notice when a validator’s role was changed to “pending”. That short window has grown to 6, 14, 23, etc. epochs.
It is also now possible to even know when a validator will be assigned “pending” in n number of epochs ahead of that increasing window. This opens the network and validators up to potential exploitation.

This validator, currently in the Waiting List at position 51 for Epoch 3480, will be assigned to a shard waiting list in Epoch 3482; it will not do so in Epoch 3481. In Epoch 3481 (the next epoch) it will move up to position 1. (This will happen around block ~175 of 3481 +/- 25 blocks)
That kind of forecasting for “pending” was not previously possible. It is now. And it can be exploited to potentially attack the network. The only randomness now is which shard a validator will be assigned. The “when” of candidate selection is no longer a random unknown. Not while the Waiting List is fixed and unshuffled.
7 Likes
My node status is pending with stalling on 2nd shard.

I don’t have the ability to access the pNode as this is just a plug and play. I appreciate everyone’s suggestions but it is useless to me when all I have is a pnode on the Internet connection.

Similarly, my vnode has been stalled in Shard 0. My other vnodes in the other shards are OK. I had deleted everything for the stalled node. I think there is another problem for Shard 0.
Well now we have a new problem @Support . My node earned on the last two epochs, and I even got notifications from the app. But, my node shows a zero balance. Node also went back to pending instead of waiting.
I did a RPC to double check it wasn’t just the app, but my balance shows zero there too.


My pNode has now stalled at shard 6, running latest firmware and already wiped the data 2 days ago.

Hey @Thriftinkid
Once we have more slots in a committee by releasing fixed nodes, the community nodes will benefit from this by being able to earn more rewards in general. But I think we still need to keep the number of swapping nodes as small as we do now. The rationale of it is mostly about the network stability: if we swap in a big number of unhealthy nodes at a time, the probability of insufficient votes for a newly proposed block would increase which might take shards (so does the network) down until these bad nodes get slashed. That’s not to mention network security yet.
In my opinion, staking to the network and earning rewards from it is a long-term investment. At the end of the day, the ROI should be the same for either big or small swapping numbers. That being said, with a small swapping number, a node has to wait longer to be in a committee but will also be in there longer and earn more rewards. Conversely, with a big swapping number, the node may get into a committee sooner but will get out of it sooner and earn less in an earning cycle. Please note that in Incognito, when running long enough on a stable set of nodes, the total rewards of each node should be approximately the same regardless of swapping number due to the normal distribution of the randomness.
I guess, after enabling slashing for a period of time, the number of nodes in the network will decrease significantly but these will contribute meaningfully to the network. So the operational nodes may earn more then.
1 Like
Also, @khanhj, please read through problems posted in the topic and prioritize your time to answer and support these cases. thanks.
2 Likes
I just hit the same problem on the same shard and the same block. I’m going to attend to delete all data and resync. I’m hoping these issues get resolved soon. This is my second resync in a week. I’ll reply if it fixes the issue.

1 Like
I believe my nodes fixed their own shard stall. I don’t believe it’s needed to delete all data.
How long did you have to wait. Mine was stalled for ~14 hours before I did the delete.
I’m not sure. I just know I had a bunch stalled and then checked later and they had fixed themselves.
Mine pNode is syncing Beacon, but stalling on Shard 3…
I can “delete the data” again, if you want, but it looks like that may not be the fix from what I am seeing in the comments.
It would be beneficial to have an announcement in app if there is a firmware update for pNode users, or tag everyone in this post that has shown this as an issue (IMHO).