
In the next release, we will support several modes aiming to reduce Incognito node’s disk usage.
1/ FFStorage mode (–ffstorage)
In previous versions, each block and transaction was not optimally encoded, causing a significant increase in storage capacity. We used LevelDB to store them, as well as all other blockchain data, causing massive CPU and RAM consumption every time LevelDB compresses stale data. In this version, we encode blocks and transactions with protobuf, reducing data storage capacity. We also introduced a flat-file system to replace LevelDB in storing block data, to ensure that other data types will not affect the block saving process. Unfortunately, in order to use this version, you need to delete the old data and perform the synchronization process again. The synchronization in this version is also faster than the old version.
2/ Batch-Commit mode (–sync-mode batch commit)
We use Ethereum stateDB to maintain our feature database (transaction, consensus). It allows Incognito to maintain states in any checkpoint which helps us debug, change view, and look up states in the past. Ethereum StateDB use Modified Merkle Patricia Trie (MPT) to organize the data objects as a tree which has some limitations:
- When the number of records reaches a certain threshold, Leveldb compression is frequently enabled. The MPT generates a large number of branch nodes, which are used to construct the tree. These nodes just hold routing data, not actual data. Creating a record for each node not only consumes database space but also slows the operation down.
- Deleting these records requires an extensive offline process.
To reduce the number of records persisted into disk, we implement a batch commit mechanism. Once a block is inserted, the node will not commit trie data to disk immediately. Instead, commit trie data to disk per batch block. By committing to disk at the last insertion time, we can build only one branch node for two or more leaf nodes with the same prefix. To put it another way, we’ll wait until a large amount of nodes are installed before committing everything to disk. Prior to then, nodes were simply committed to memory. This mode is similar to Ethereum full-sync mode.
3/ Lite mode (–sync-mode lite)
Ethereum-based StateDB implementation allows clients to revert state at specific points in the past. However, there are types of database that node operation doesn’t need this functionality, such as transaction DB. With MPT, there is overhead of internal data structure that makes disk size increase not linearly. In addition, retrieving a value in MPT will need several disk IO.
To support users running low cost nodes, we implement a hybrid data structure, called lite-statedb. As a hybrid mechanism, finalized states are stored in key-value DB, and an unfinalized state (multiview) in link list data structure.
By only persisting the final value, this method does not pose any overhead to the database, but the tradeoff is the node cannot retrieve state in the past.
Result
Here is the result after we benchmark.
- Old:the current version code
- Archive: the default mode (commit every block), but with ffstorage enabled
- Batch: batch-commit mode with ffstorage enabled
- Lite: lite mode with ffstorage enabled
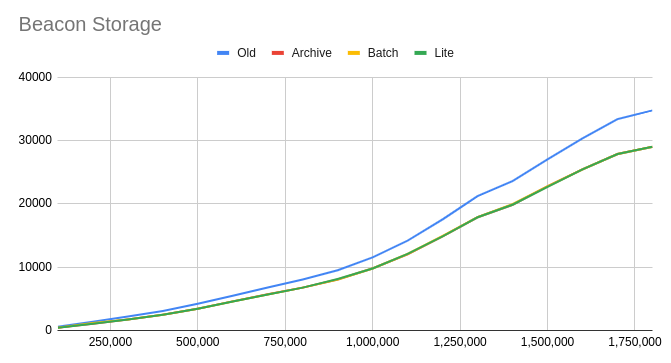
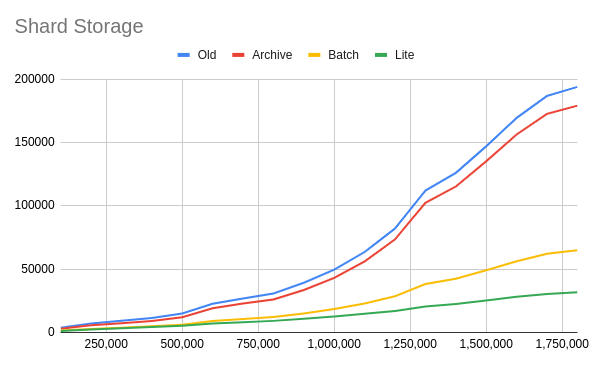
From the result, we see that beacon db size is only affected by ffstorage mode (reduce 15%), as it does not have any stateDB that can run in batch-commit or lite mode. On the other hand, shard db size is significantly reduced as its transactionDB can be applied batch or lite.
Regarding the full node database, all shard chains will be reduced 3 times if using batch-commit, and 5 times if using lite mode. And overall, a full node can reduce to 50 - 70% data size.
Note on release
Although these features are tested in several environments, it is not battle-tested yet. To reduce risk to our whole blockchain, we will not apply this feature in production-branch yet, but beta branch instead. There are 3 phases to release:
- Core & community volunteer (2 week): core team will run several nodes with new modes, and we welcome any volunteer from community running new modes with us
- Partial foundation node (2 week): a portion of fixed node will be upgrade new modes
- Full upgrade: these features will be merged and applied in production code.
We recommend that node operators should run at least 1 node with production-branch. In case of bug or db corruption of the beta-branch, you can clone and revert to the production-branch.
The branch and docker tags for this feature will be announced later.


 The difference is that it just uses the new feature ffstorage.
The difference is that it just uses the new feature ffstorage.